
来源:https://blog.csdn.net/weixin_44329069/article/details/143760411
大语言模型系列是笔者学习过程中的笔记,很多来自网络文档,如有侵权请随时告知。
大语言模型开发的三个阶段:构建、预训练、微调
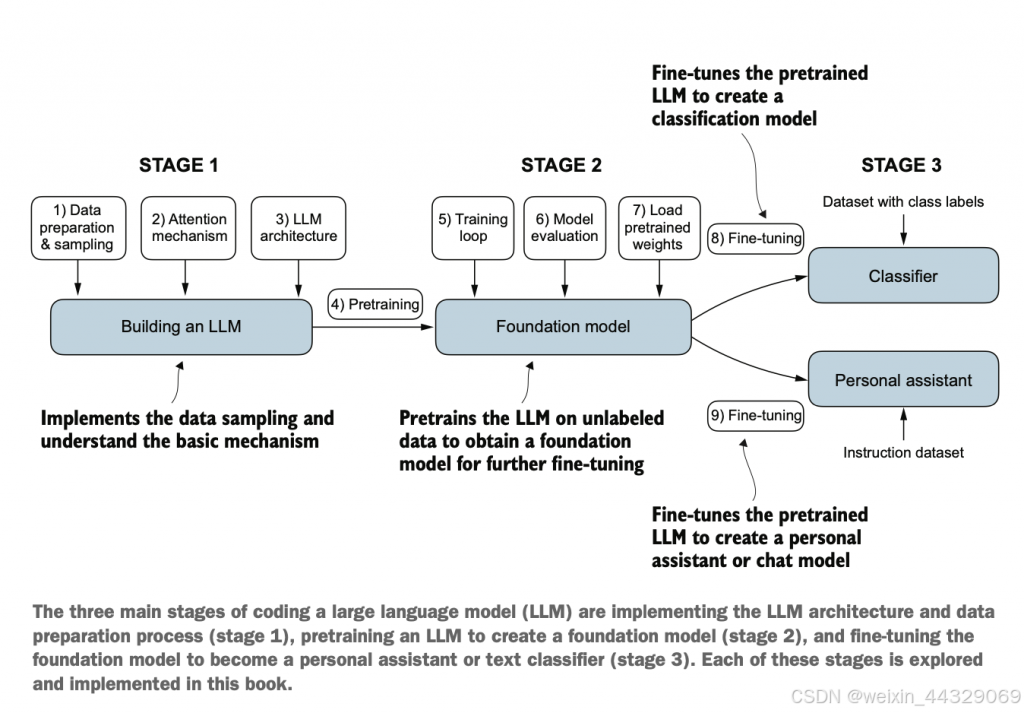

第一阶段:LLM的基础构建
1)数据准备和采样(Data preparation & sampling):这一步骤主要是收集和处理数据。因为大语言模型需要大量的数据来进行训练,所以这里的数据准备包括采样、清洗和标注等过程。
2)注意力机制(Attention mechanism) :实现并理解注意力机制是构建LLM的关键步骤。注意力机制允许模型更好地理解句子中的重要词汇及其关系。
3)LLM架构设计(LLM architecture):这一步是设计模型的整体架构,包括层数、维度、编码方式等。常见的架构有Transformer、BERT、GPT等。
4)预训练(Pretraining): 在完成前几步之后,将模型在大量无标签数据上进行预训练。这是为了让模型学习到语言的基本结构和词汇关系。
在这个阶段结束之后,得到了一个基础的LLM,实现了数据采样、注意力机制和架构的基础。
第二阶段:构建基础模型(Foundation Model)
5)训练循环(Traing loop):这一阶段的核心是建立训练循环。模型会在大量数据上进行训练,逐步优化参数,使其在语言任务上表现的更好。
6)模型评估(Model evaluation):训练过程中,需要定期评估模型性能,查看是否收敛或是否需要调整超参数。
7)加载预训练权重(Load pretrained weights):在一些情况下,可以加载已有的预训练权重进行微调,避免从头开始训练。
在这个阶段末尾,得到了一个基础模型(Foundation Model),可以用作进一步任务的微调(Fine-tuning)。
第三阶段:微调模型
8)微调分类器(Fine-tuning for classification): 在一些任务中,基础模型会被微调以实现分类功能。这里需要一个有标签的数据集,通过训练让模型能够准确分类。
9)微调为助手模型(Fine-tuning for a personal assistant):在其他任务中,可以将基础模型微调为一个助手或对话模型,通过带有指令的数据集训练,让模型能够回答问题或提供交互支持。
最后经过微调后得到了特定任务的模型,例如分类其或个人助手(聊天模型)。