
参考文档:https://blog.51cto.com/u_15840342/12188908
什么是tokenizing?
就是将文本数据转换为代表文本的数字,一般是基于字符出现的频率。
需要注意:编码和解码的tokenizer需要保持一致,一般训练的模型有自己专属匹配的tokenizer.
tokenizer 分词器 token 词语

实现LLM生成和更新专属嵌入的关键步骤参考下图:
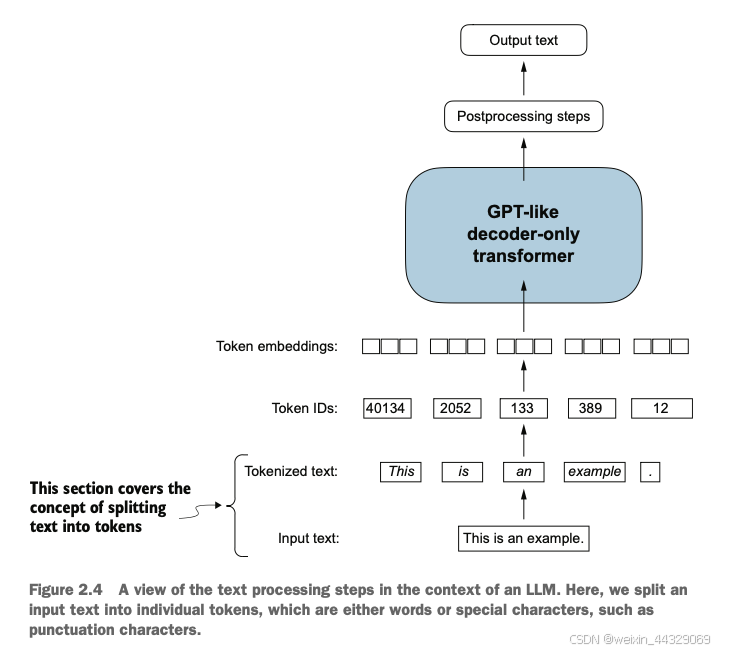
关键步骤如下:
1)构建嵌入层:在LLM的输入层色合计一个嵌入层(通常是nn.Embedding层)。这个嵌入层会将输入的词或子词的离散表示(如词汇表索引)映射为连续的高维向量。不同与word2vec的固定嵌入,这里的嵌入向量是初始化后会不断调整的。
2)随机初始化嵌入向量:嵌入层的向量最初是随机初始化的,随着训练不断优化。这个随机初始化是的LLM在训练初期不会带有任何偏见,也让它能更灵活的学习特定任务的语义关系。
3)训练过程中的自适应优化:在LLM的训练中(如在预测下一个词的过程中),通过反向传播不断调整嵌入层的权重。每次迭代的时候,嵌入会根据损失函数进行更新,使得嵌入向量逐步对当前任务的需求和数据结构更加敏感,从而提升模型在具体任务上的表现。
4)上下文敏感的词嵌入:LLM还会生成上下文敏感的嵌入,意味着词的表示会随着不同的上下文而动态调整,使模型能够在不同语境下理解词的不同含义。这些嵌入在训练中不仅适用于当前数据,还能够适应与次任务相似的其他任务。