
智能运管首先需要完成的是各类运维数据的采集和存储,之后才是在此基础上开展各种分析处理工作。因此本文开宗明义首先说的就是如何实现运维数据采集和存储。
运维数据分类
笔者认为,运维数据可以分为两大类:运维指标类数据和运维日志类数据。
- 运维指标类数据是指各种的key-value键值对,例如 针对主机性能监控的 cpu利用率、内存利用率、网络可访问性以及带宽等等。
- 运维日志类数据则是指各种系统、设备产生的日志信息,以时间+文本为主,例如apache的web服务产生的日志,操作系统产生的系统日志以及网络设备产生的netflow数据、DNS数据等等诸如此类。
针对不同类型的数据,需要采取不同的数据采集方式,接下来分别展开介绍。
运维指标类数据采集与存储
实际上各类运维指标数据的采集已经有多种采集软件,例如 Zabbix、Nagios、Cacti、Ganglia、Open-Falcon以及Prometheus等。此处笔者不展开一一介绍,只是直接说结论:如果是首次接触此类内容,那么不用犹豫,直接上Prometheus。
Prometheus(普罗米修斯)是由前google员工2015年正式发布的开源监控系统,采用Go语言开发。它不仅有一个很酷的名字,同时它有Google与k8s的强力支持,开源社区异常火爆。其官网地址为: prometheus.io 。
笔者认为Prometheus相关组件比较齐全,形成了一整套完整的流程。
在被监控端(例如被监控主机)部署各类Exporter,例如node-exporter 用于监控主机指标
然后单独部署Prometheus,实现对各个Exporter的数据采集,在本地缓存之后,进行提交
如果是存在多个Prometheus,需要对采集到的指标进行汇聚,则可以用到Thanos实现,并实现存储到对象存储系统中。
而且Prometheus和Thanos都提供查询接口,两者的查询语句和存储结构基本上类似,不会增加太多难度。
所以这条技术路线基本上是:
exporter —-> Prometheus —-> Thanos —-> OSS
具体每个部分的部署方法后续会逐步展开,并在此文中添加相关的链接。
运维日志类数据采集与存储
日志类运维数据是指系统所指定的对象的某些操作和其操作结果按照时间序列的集合,意即日志文件。记录了系统/应用/服务与用户之间交互的信息。日志文件为服务器、工作站、防火墙和应用软件等 IT 资源相关活动记录必要的、有价值的信息,这对系统监控、查询、报表和安全审计是十分重要的。日志文件中的记录可提供以下用途:监控系统资源;审计用户行为;对可疑行为进行告普;确定入侵行为的范围;为恢复系统提供帮助;生成调查报告;为打击计算机犯罪提供证据来源。因此非常有必要对重要的运维Log日志数据进行汇聚和持久化存储。
针对大规模的日志数据,需要采用分布式架构予以实现,此前业内较为经典的架构有如下三种:
(1) ELK架构
也就是现在的Elastic Stack,是Elasticsearch + Logstash + Kibana + Beats的组合,其中,Beats负责日志的采集, Logstash负责做日志的聚合和处理,Elasticsearch作为日志的存储和搜索系统,Kibana作为可视化前端展示。整体架构如下图所示:
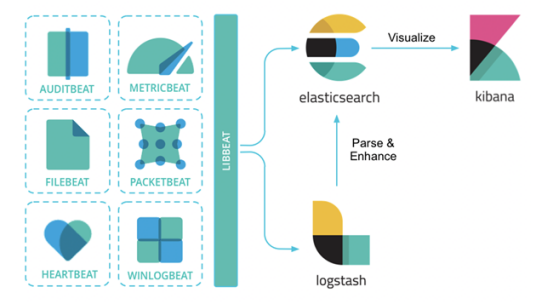
(2) EFK架构
此外,在容器化场景中,尤其是在Kubernetes环境中,用户经常使用的另一套框架是EFK架构。其中,E还是Elasticsearch,K还是Kibana,其中的F代表Fluent Bit,一个开源多平台的日志处理器和转发器。Fluent Bit可以让用户从不同的来源收集数据/日志,统一并发送到多个目的地,并且它完全兼容Docker和Kubernetes环境。
(3) PLG 日志系统
但是,Grafana Labs提供的另一个日志解决方案PLG目前也逐渐变得流行起来。PLG架构为Promtail + Loki + Grafana的组合,整体架构图下所示:
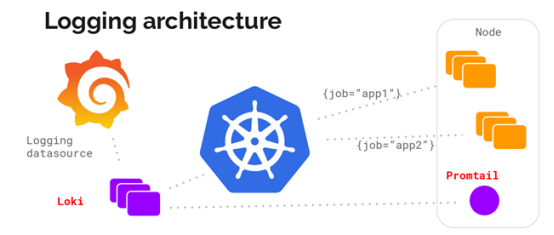
笔者实际工作过程中采用的事第三种方案,即PLG架构。
今天先简单从整体上概述一下整个运维数据的采集架构和所采取的方法。至于各个部分的详细情况以及具体部署方法,会在后续逐步一一介绍。